
10 Regeln für Microservice Logging
In einer Microservice Architektur entstehen oftmals große Herausforderungen insbesondere, wenn es um Monitoring und Logging geht. Da wir bei PIPEFORCE eine Lösung entwickelt haben, die Logs von unseren Microservices auf halbautomatische Weise sammelt und aufbereitet, möchten wir unsere Erkenntnisse, die wir in den vergangenen Jahren gesammelt haben, teilen. Aus diesem Grund haben wir die unserer Meinung nach 10 wichtigsten Regeln zum Thema Microservice-Logging zusammengefasst und uns auf diejenigen beschränkt, die für eine erfolgreiche Implementierung in einer Microservice Architektur notwendig sind.
Herausforderungen der Microservice Architektur
Vereinfacht ausgedrückt wird eine monolithische Anwendung als eine einzige, einheitliche Einheit aufgebaut, während eine Microservices-Architektur eine Sammlung kleinerer, unabhängig voneinander einsetzbarer Dienste darstellt. Die Überwachung und Protokollierung in einer monolithischen Anwendung ist so einfach wie das Veröffentlichen von Daten in einer einzigen Protokolldatei und das spätere Abrufen dieser Daten. Bei der Arbeit mit Microservice-basierten Anwendungen gibt es jedoch viele Herausforderungen aufgrund der erhöhten Komplexität ihrer verteilten und lose gekoppelten Kommunikation. Eine große Herausforderung besteht darin, dass es keine zentrale Stelle gibt, die die Protokolle erzeugt, sondern ein ganzer Ausführungsfluss, der sich zwischen verschiedenen Microservices verschiebt, was ziemlich schwierig zu verfolgen und zu überwachen sein kann. Ein Beispiel soll zur Veranschaulichung dienen.
In einem Cluster laufen drei Microservices. Ein Microservice ‘A’ führt einen Befehl aus und sendet eine Anfrage an den Microservice ‘B’. Der Microservice ‘B’ führt einige Arbeiten aus und sendet seine eigene Anfrage an einen anderen Microservice ‘C’. Schließlich werden die Antworten in dieser Reihenfolge erzeugt: C->B, B->A. Hier wird bereits ersichtlich, dass dies ein großes Problem bei der Nachverfolgung darstellt, da man die sequenziellen Ausführungen all dieser Microservices überwachen und protokollieren muss. Man muss wissen, welcher Microservice zu welchem Zeitpunkt ausgelöst wurde. Welche Ausführung hat er durchgeführt? Welcher übergeordnete Microservice hat diesen Microservice ausgelöst? All diese Tracing-Informationen sind von entscheidender Bedeutung, insbesondere dann, wenn ein Microservice oder ein Prozess abstürzt und man ihn debuggen muss.
Um es auf den Punkt zu bringen: Monitoring und Logging sind zwei unterschiedliche Ansätze. In erster Linie ist die Protokollierung eine passive Aktivität, die beobachtete Daten aufzeichnet. Die Überwachung hingegen beinhaltet mehr, da sie diese Daten untersucht und nach Mustern, Änderungen oder anderen nützlichen Informationen über die Anwendungsleistung sucht. Sogar das Auslösen eines Alarms, wenn die Werte über einen bestimmten Punkt steigen, wird als Überwachung betrachtet. Die Protokollierung kümmert sich allerdings nicht um die Daten, die aufgezeichnet werden. Das bedeutet, dass die Protokollierung die Daten nicht nutzt, sondern nur Protokolleinträge in einem bestimmten Format erstellt.
Wir bei PIPEFORCE haben eine Lösung entwickelt, die Logs von unseren Microservices auf halbautomatische Weise sammelt und aufbereitet und möchten unsere Erkenntnisse, die wir während dieses Prozesses gesammelt haben, gerne teilen. Daher folgen nun die unserer Meinung nach 10 wichtigsten Regeln zum Thema Microservice-Logging.
Regel 1: Schreibe Logs in die Konsole, nicht in Dateien
Ein häufiger Fehler bei Microservices ist, dass man in eigene Logdateistrukturen mit eigenen Benennungs- und Aufbewahrungsregeln loggt. Das macht es sehr schwer, den Ort der Protokolle für jeden Microservice zu erkennen, da diese Bedingungen für jeden einzelnen Microservice unterschiedlich sein können. Wenn man 10 oder Hunderte davon hat, sollte man sich gut überlegen, wie dies im Laufe der Zeit verwaltet werden sollte und nicht versuchen die Protokolldateien eines jeden Dienstes auswendig zu wissen. Stattdessen solltest du deine Logs einfach in die Konsole schreiben. Die meisten Cloud-nativen Umgebungen wie Kubernetes können diese Protokollausgaben automatisch erkennen und sammeln. Du kannst dann ein einziges Tool wie z. B. kubectl verwenden, um diese Protokolle aufzulisten und zu gruppieren. Es ist nicht notwendig, zusätzliche Mappings vorzunehmen, Adapter zu schreiben oder Konfigurationen vorzunehmen. Darüber hinaus solltest du informative Log-Meldungen wie INFO oder DEBUG in die Standardausgabe und Fehlerprotokolle wie WARN, ERROR oder FATAL in die Fehlerausgabe schreiben. Auf diese Weise können die Cloud-nativen Frameworks eine grobe Gruppierung der Logouts nach ihrer Wichtigkeit vornehmen.
Regel 2: Verwende ein Logging-Framework
Wie in Regel 1 erwähnt, empfehlen wir, auf der Konsole zu protokollieren, aber das bedeutet nicht, dass man Code direkt mit der Konsolenausgabe verknüpfen sollte, sondern stattdessen ein Logging-Framework verwenden sollte, das dies für dich erledigt. Es klingt offensichtlich, aber wir haben schon zahlreiche Anwendungen gesehen, die Log-Meldungen einfach direkt auf die Konsole schreiben, indem sie console.log oder system.out Anweisungen verwenden. Dies ist keine gute Idee, da dadurch der Anwendungscode direkt mit der Ausgabe verknüpft wird und die Anwendung dadurch viel schwieriger zu testen und zu warten ist. Stattdessen bietet ein Logging-Framework die Möglichkeit, die Log-Levels zu spezifizieren. Die Ausgabe ist in der Regel leistungsoptimiert, es kann das Format der Log-Ausgabe anhand von Mustern ändern und schließlich kann es je nach Umgebung zwischen den Zielen wechseln. Man möchte ja beispielsweise z.B. in der lokalen Entwicklung eine andere Log-Ausgabe sehen, als wenn die Anwendung in der Produktion innerhalb eines Clusters läuft.
Regel 3: Protokolliere nach Möglichkeit im JSON-Format
Ein großes Problem bei Protokolldateien ist, dass die Textdaten unstrukturiert sind. Damit Protokolldateien jedoch maschinenlesbar sind, müssen sie in einem strukturierten Format vorliegen. Daher ist es schwierig, die Protokolleinträge zu filtern und zu Analysezwecken abzufragen. Es wäre viel besser, wenn Entwickler in der Lage wären, Protokolle auf der Grundlage eines Feldes zu filtern. Das Ziel der JSON-Protokollierung ist es, diese und viele andere Probleme zu lösen. Das JSON-Format ist leicht lesbar und wird von fast allen Überwachungstools unterstützt. Das Hauptziel der Verwendung des JSON-Formats für die Protokollierung besteht darin, die Protokolle besser lesbar und parsierbar zu machen. Wenn du ein Schema mit vielen Feldern hast, ist das Schema für das menschliche Auge lesbar. Wenn man allerdings ein kompliziertes Schema in den Protokollen hat, kann man wichtige Informationen leicht übersehen. Um das zu vermeiden, füge nur Objekte in dein JSON ein, die du auch lesen solltest. Man kann zum Beispiel alle eingehenden Anfrageparameter in einem einzigen Feld kodieren. Wenn du sie als einzelne Felder sendest, stiftet das häufig Verwirrung.
Regel 4: Zentralisiere und indiziere deine Protokolle
Bei der zentralen Protokollierung werden Protokolle von Netzwerken, Infrastrukturen und Anwendungen an einem einzigen Ort zur Speicherung und Analyse gesammelt. Auf diese Weise erhalten Administratoren einen konsolidierten Überblick über alle Aktivitäten im gesamten Netzwerk, was die Identifizierung und Behebung von Problemen erleichtert.
Die Indizierung von Protokollen ist eine Methode der Protokollverwaltung, bei der Protokolle auf der Grundlage bestimmter Attribute als Schlüssel angeordnet werden. Suchmaschinen sind für die Indizierung von Protokollen verantwortlich, damit der Zugriff auf diese Protokolle durch Abfragen oder Suchen schnell und optimiert erfolgen kann. Sobald die protokollierten Ereignisse indiziert sind, stehen sie für die Suche und Filterung bereit. Für die Indizierung und Durchsuchung von Protokollen stehen zahlreiche Tools/Frameworks zur Verfügung, wie Apache Solr, Elasticsearch, Kafka, OpenSearch usw.
Regel 5: Behandle Protokolle wie Ereignisströme
Es empfiehlt sich, Systemprotokolle (z. B. Systemfehler, Probleme bei der Codeausführung oder Aktualisierungen usw.) sowie Geschäftsereignisse (z. B. für Prozesse wie Dateidownload, Konvertierung von csv in json, Senden einer E-Mail usw.) auf die gleiche Weise zu behandeln. Systemprotokolle werden oft in Protokolldateien erfasst, während Geschäftsereignisse oft in einer Ereigniswarteschlange erfasst werden. Beide sollten jedoch in demselben Stream erfasst werden. So gibt es nur einen Stream, der alle Informationen über die Anwendung abdeckt. Das macht es einfacher, die Ereignisse herauszufiltern, die für eine bestimmte Frage oder Analyse wichtig sind. Für Analyse-/BI-Zwecke können wir also einfach Systemprotokolle und Geschäftsereignisse herausfiltern, wo immer es angebracht ist.
Regel 6: Keine sensiblen Daten und Datenschutzdaten protokollieren
Im Mai 2018 teilte Twitter mit, dass das Unternehmen eine Schwachstelle entdeckt hat, durch die Nutzerdaten unbeabsichtigt in das Protokollierungssystem eingegeben wurden. Ein Jahr später forderte Facebook alle Nutzer auf, ihre Passwörter zu ändern, nachdem lesbare Passwörter auf dem internen Datenspeicher entdeckt worden waren. Obwohl in beiden Fällen keine Datenkompromittierung stattfand, wurden die Daten dennoch protokolliert. Auch wenn keine Sicherheitsverletzung vorlag, waren personenbezogene Daten dennoch gefährdet, denn jede/r, der Zugriff auf das Protokollierungssystem hatte, hätte sich möglicherweise Zugang zu sensiblen Verbraucherdaten verschaffen können.
Sensible Daten sind alle Daten, mit denen eine Person identifiziert werden kann (auch PII, Personally Identifiable Information genannt). E-Mail-Adresse, Name, Geburtstag, Sozialversicherungsnummer, IP-Adresse, ethnische Zugehörigkeit, Geschlecht, IP-Adressen, Benutzernamen und Passwörter, Kreditkarteninformationen und alle anderen personenbezogenen Daten gelten als sensibel.
Die Protokollierung ist für die Fehlersuche, das Störungsmanagement und die Behebung von Fehlern unerlässlich. Die Aufzeichnung sensibler Daten wirft jedoch eine Reihe von Problemen auf, darunter auch der Schutz der Privatsphäre der Beteiligten, rechtliche Beschränkungen für die Erfassung persönlicher Informationen und die Möglichkeit der Offenlegung von Daten durch Insider. Unternehmen müssen festlegen, welche Daten gesichert werden müssen, und eine Datenklassifizierungsrichtlinie entwickeln, um die Daten entsprechend ihrer Sensibilität zu kategorisieren. So können sie die Daten herausfiltern, die protokolliert werden müssen, und den Rest verwerfen.
Regel 7: Gemeinsame Protokollebenen verwenden
Verwende die üblichen Protokollebenen wie DEBUG, INFO, WARN, ERROR und vermeide spezielle Ebenen, da sie später schwer zuzuordnen sind. Wenn möglich, stelle sicher, dass alle Microservices die gleichen Namen für die Ebenen verwenden oder zumindest eine Zuordnung leicht möglich ist.
Regel 8: Verwende eine Korrelation / Trace-ID
Die Protokollierung kann auch dazu verwendet werden, die Interaktion zwischen verschiedenen Diensten oder das Tracing zu erfassen. Verschiedene Dienste können Anfragen an andere Dienste senden, um bestimmte Prozesse oder Ereignisse auszuführen. Diese Anfragen müssen in einer sequentiellen Weise verfolgt werden.
Eine Korrelations-ID ist ein eindeutiger, zufällig erzeugter Identifizierungswert, der zu jeder Anfrage und Antwort hinzugefügt wird. In einer Microservice-Architektur wird die anfängliche Korrelations-ID an Ihre Unterprozesse weitergegeben. Wenn ein Subsystem auch Sub-Anfragen stellt, wird die Correlation ID auch an diese Systeme weitergegeben. Wie man die Korrelations-ID an andere Systeme weitergeben, hängt von der Architektur ab.
Google hat Dapper für kontinuierliches und allgegenwärtiges Tracing mit geringem Aufwand, Anwendungstransparenz und Skalierbarkeit. Betrachten wir eine Architektur mit einem Front-End, Middle-Tier und Back-End, die Anfragen und Antworten miteinander austauschen. Dapper verwendet drei IDs, um alles zu verfolgen:
- Parent id: Span id des auslösenden Spans
- Bereichs-ID: identifiziert einen Bereich oder RPC (Remote Procedure Call)
- Trace id: identifiziert die auslösende Anfrage
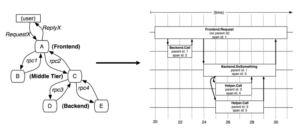
Auf diese Weise ist die Korrelations-ID oder Trace-ID sehr wichtig für die Verfolgung innerhalb einer Architektur von ständig interagierenden Diensten und zu erstellen sowie aufzubewahren. Dieser Trace-Kontext kann in einem thread-lokalen Speicher abgelegt werden, so dass er bei entsprechenden Callbacks automatisch übermittelt werden kann. Wenn ein Callback aufgerufen wird, kann der Trace-Kontext in den ausführenden Thread kopiert werden. Neben Dapper gibt es weitere Frameworks und Spezifikationen für das Log-Tracing wie z.B.: W3C Tracing, Sleuth und andere. Welches am besten passt, hängt von deinen Anforderungen ab.
Regel 9: Verwende ein Reporting-Tool
Wenn alle Protokolle verarbeitet und in einem zentralen Speicher abgelegt sind, können sie zur Erstellung von Visualisierungen und Berichten für Business Intelligence verwendet werden. Es gibt viele Reporting-Tools, wie Kibana, Tableau, SAP, etc.
Das ideale Reporting-Tool sollte Folgendes unterstützen:
- Ein Dashboard (idealerweise mit vorgefertigten Berichten wie Balkendiagrammen, Tortendiagrammen, Tabellen, Histogrammen und Karten)
- Eine Abfragesprache, um tief in Protokolle einzutauchen
- Warnungen
- Strukturierte / JSON-Protokolle
Regel 10: Behalte die Komplexität und Leistung im Auge
Das Senden und Sammeln von Protokollen von vielen Microservices kann zu einem großen Leistungsproblem werden. Stelle sicher, dass Techniken wie Stapelverarbeitung, Komprimierung und Zwischenspeicherung verwendet werden, wo immer möglich.
Stelle außerdem sicher, dass du eine Infrastruktur verwendest, die je nach den Protokollanforderungen automatisch skaliert werden kann.
Verwende zudem nach Möglichkeit ein Tool, mit dem du die Protokollierung sofort einrichten kannst, damit du dich auf deine Kernaufgaben konzentrieren kannst, wie z. B. PIPEFORCE. Um weitere Informationen darüber zu erhalten, wie dies mit PIPEFORCE funktioniert, kannst du ganz einfach auf unserer Website eine Demo buchen.
Zusammenfassung
Monitoring und Logging in einer Monolith-Anwendung sind im Vergleich zu einer Microservice-Architektur aufgrund der Komplexität der Interkommunikation relativ einfach. In dieser Hinsicht gibt es 10 Hauptregeln, die zu befolgen sind, wenn du Monitoring und Logging innerhalb einer Microservice-basierten Plattform durchführen willst. Diese Regeln sind wichtig, um häufige Fehler zu vermeiden, die zu einem schwer zu verwaltenden Durcheinander führen würden. Wenn man zum Beispiel Protokolle in verteilten Dateien ablegt, führt dies zu Verwirrung, wenn man versucht, diese Protokolle zu finden. Ebenso ist es ohne die Verwendung eines TraceID-Indentifiers unmöglich, den Ablauf von Back-to-Back-Prozeduraufrufen zurückzuverfolgen. Die meisten dieser Regeln sind in die PIPEFORCE-Lösung integriert, um zukünftige Fehler in einer Microservice-Architektur zu vermeiden und einen reibungslosen, optimierten und nachvollziehbaren Ablauf zu gewährleisten.
Vereinbare hier deinen kostenfreien Beratungstermin, um nähere Informationen dazu zu erhalten.
PIPEFORCE
Die Münchner Plattform PIPEFORCE ist eine umfassende Lösung für die Modellierung und Automatisierung von unternehmensindividuellen Geschäftsprozessen. Die Plattform ist speziell auf die Anforderungen von mittelständischen und großen Unternehmen ausgerichtet und unterstützt durch einen durchgängigen Ansatz den Gesamtprozess vom Workflow-Design bis zur digitalen Umsetzung. Mit dem einzigartigen Pipeline-Ansatz wird die Integration von Systemen und die Verarbeitung von Daten und Dokumenten extrem flexibel und einfach abgebildet, so dass auch technisch anspruchsvolle Automatisierungen innerhalb kürzester Zeit umgesetzt werden können. UiPath einfach in die Systemlandschaft integrieren – mit PIPEFORCE.





